网络爬虫是什么?
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引。网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。
—上述概念来源维基百科
但是本文讨论的网络爬虫,狭义的指使用网络爬虫技术自动爬取网站网页中的公开数据(包括图片,文字等)并保存到自己的计算机系统的过程。
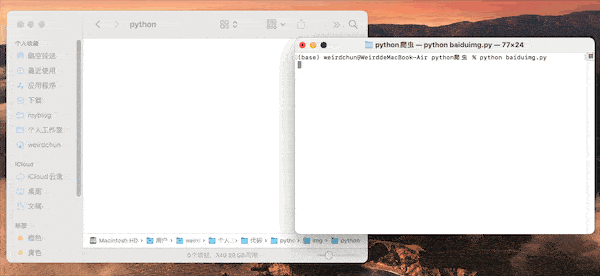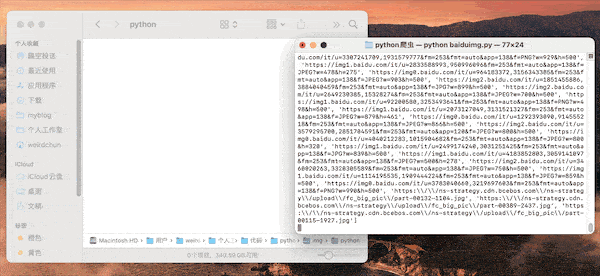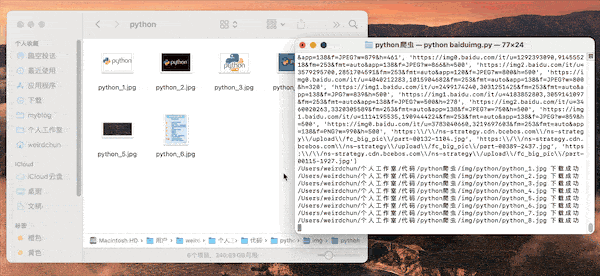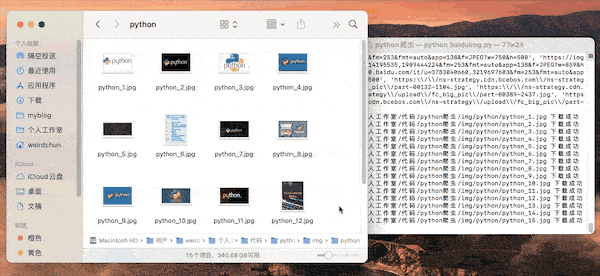
如下图,使用python代码可以自动爬取并下载百度图片。
网络爬虫是否构成犯罪?可能构成什么犯罪?
笔者在裁判文书网(https://wenshu.court.gov.cn)上以“网络爬虫”为关键词,并限定在“刑事案由”进行检索,一共有10篇相关的判决。(笔者检索时间为2023年4月13日,其中最早的判决于2015年2月27日,最新的判决于2022年8月15日)
十篇判决书的标题分别是:
| 判决书标题 | 案 号 |
|---|---|
| 肖俊侵犯著作权罪刑事一审刑事判决书 | (2022)赣0825刑初2号 |
| 林镇平等非法获取计算机信息系统数据一审刑事判决书 | (2020)京0105刑初2594号 |
| 赵海畅非法获取计算机信息系统数据一审刑事判决书 | (2020)京0105刑初1289号 |
| 吴俊南、刘俊非法获取计算机信息系统数据、非法控制计算机信息系统一审刑事判决书 | (2020)粤0305刑初1037号 |
| 被告人周华侵犯公民个人信息罪一审刑事判决书 | (2019)湘1202刑初530号 |
| 杨杰明、张国栋破坏计算机信息系统一审刑事判决书 | (2019)粤0305刑初193号 |
| 马适之、郭靖二审刑事判决书 | (2018)鄂05刑终365号 |
| 马适之、张立一审刑事判决书 | (2018)豫9001刑初503号 |
| 魏江蒙侵犯公民个人信息一审刑事判决书 | (2018)鄂0528刑初52号 |
| 黄后荣、翁秀豪非法获取计算机信息系统数据、非法控制计算机信息系统罪一审刑事判决书 | (2014)杭余刑初字第1231号 |
从标题可以看出,涉及的罪名有:侵犯著作权罪、侵犯公民个人信息罪、非法获取计算机信息系统数据罪、破坏计算机信息系统罪。
具体阅读了上述判决,简述法官认为当事人犯罪的行为,如下:
-
在侵犯著作权罪案件中,犯罪行为是通过网络爬虫,爬取拥有版权网站的数据内容,把数据内容放在自己的网站程序中获取收益,侵犯了他人的著作权。
-
在侵犯公民个人信息罪案件中,犯罪行为是通过网络爬虫,爬取公民的个人信息并且进行售卖,侵犯了公民的个人信息。
-
在非法获取计算机信息系统数据罪案件中,犯罪行为是利用网络爬虫程序,采用破解验证码、绕开网站登录等手段非法获取公司数据(林镇平等非法获取计算机信息系统数据一审刑事判决书)。
-
在破坏计算机信息系统罪中,犯罪行为是利用网络爬虫高强度的访问网站,造成其他人无法正常访问。
由此可见,网络爬虫可能从三个层面构成犯罪,如下:
-
在爬取速度层面,爬虫访问的速度要有限度,过高的访问量可能会导致其他用户无法访问网站,则可能涉嫌构成破坏计算机信息系统罪。
-
在爬取内容层面,爬取的内容要合法,对于爬取公民的个人信息,即使不售卖营利,单纯的爬取行为也可能构成侵犯公民个人信息罪,即刑法第二百五十三条之一的第三款,窃取或者以其他方法非法获取公民个人信息的,依照第一款的规定处罚。
-
在爬取目的层面,使用爬虫程序获得的数据内容用于营利,可能会涉嫌构成侵犯著作权罪或侵犯公民个人信息罪。如果爬取目的是为了科研或学习,则不会构成犯罪。
总之,由于相关法律规定的细节还不够完善,法官存在较大的自由裁量空间;并且法官对相关技术原理了解甚少,可能会出现适用法律错误(比如: 某些法官认为绕开反爬虫措施爬取数据构成非法获取计算机信息系统数据罪,法官是否适用正确,可参考孙禹学者的《强行爬取公开数据构成犯罪吗?》)。如果自己不小心涉嫌犯罪,即使请的辩护律师水平很高,也会处于非常不利的情况。所以,各位技术人员使用网络爬虫技术时务必谨慎小心,避免陷入犯罪的泥潭中。